I Was About to Spend $2,000 on a New GPU. Then Google Released TurboQuant.
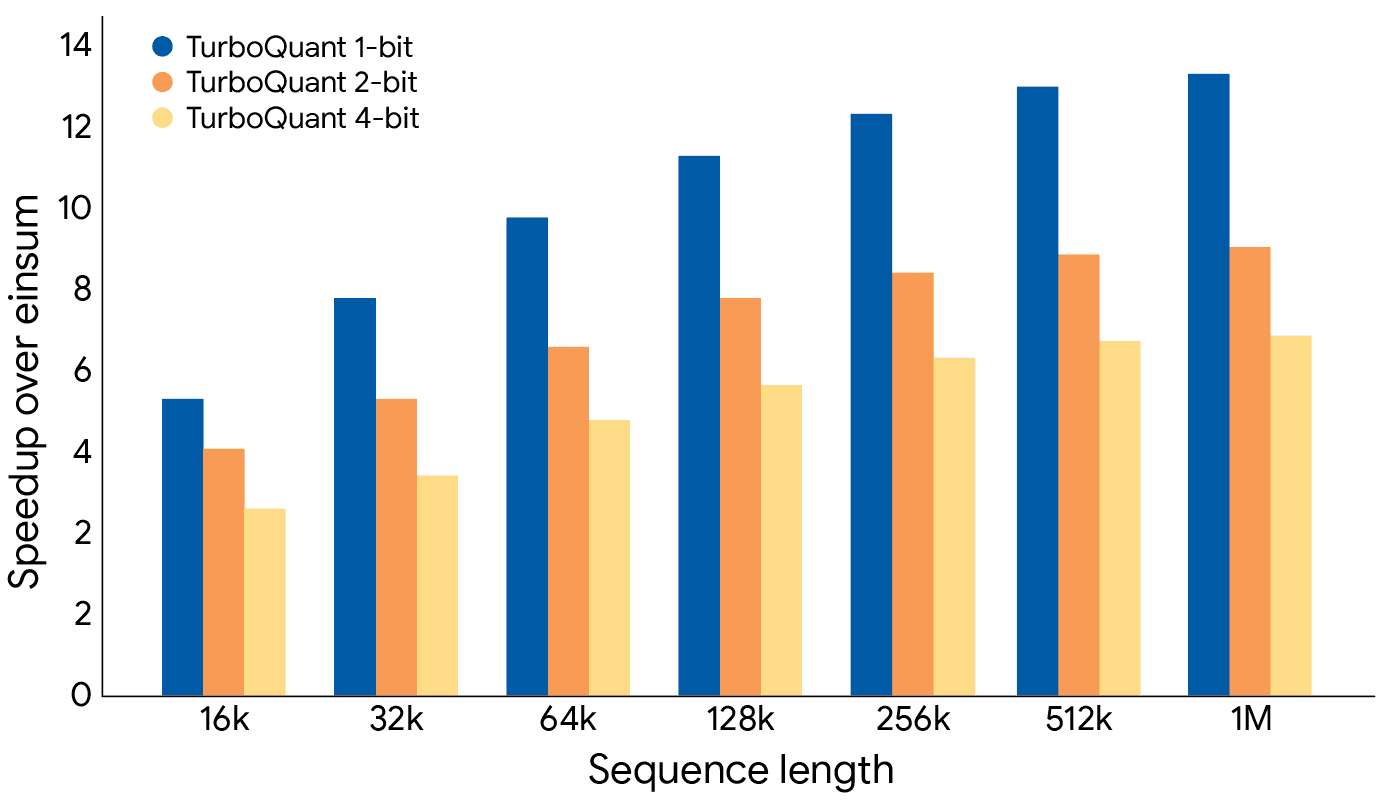
If you’ve ever fallen down the rabbit hole of local AI-running models like Llama 3 or Mistral on your own hardware-you’ve likely hit the same brick wall I did: The VRAM Wall.
I remember the first time I tried to feed a long PDF into my local chatbot. It started off great, but halfway through, my computer slowed to a crawl, the fans sounded like a jet taking off, and then... CRASH. The dreaded Out of Memory error. I honestly thought the only way out was to open my wallet and buy a high-end NVIDIA card with 48GB of VRAM.
But then, Google Research dropped TurboQuant (Zandieh et al., 2025). It’s being called the "DeepSeek moment" for memory, and after digging into the details, I finally understand why it’s going to save me (and you) a fortune.
The Invisible Memory Eater: Why "Size" Isn't Everything
When I first started, I thought that if a model was 8GB, it would fit on an 8GB card. I was wrong.
As we talk to an AI, it needs to remember the conversation. This is stored in something called the Key-Value (KV) Cache. Think of it as the AI’s scratchpad. Every word you type and every word the AI generates takes up space on that scratchpad.
The problem? As your conversation gets longer, the scratchpad grows. On some models, the KV cache can actually end up taking four times more memory than the model itself (o-mega.ai, 2026)! This is why your AI starts fast but dies during long chats. It’s not the model’s "weight" that’s the problem; it’s the sheer volume of "memories" it’s trying to hold onto.
How TurboQuant Performs Its "Magic"
I’ve looked at other compression methods before, like simple 4-bit quantization, but they usually make the AI feel like it’s had a lobotomy. It loses its "sharpness" and starts hallucinating.
TurboQuant is different because it uses a two-stage math trick that feels like a cheat code for physics.
1. The "Polar" Rotation Trick (PolarQuant)
In standard AI data, there are always "outliers"-random bits of data that are way larger than the rest. These spikes make it impossible to compress the data evenly. Google’s team figured out that if they "rotate" the data using a random matrix, they can spread that energy out. I like to visualize it like taking a crumpled piece of paper and smoothing it out perfectly flat so it fits into a thin envelope (Vasisht, 2026).
2. The 1-Bit Error Correction (QJL)
Even after the rotation, there's a tiny bit of "noise" left over. TurboQuant uses something called a Quantized Johnson-Lindenstrauss (QJL) transform. In plain English: it uses just one extra bit to store the "mistakes" made during compression. This ensures that when the data is un-squashed, it’s nearly identical to the original.
Why This Is a Personal Win for All of Us
Here is the breakdown of why I’m so hyped about this, and why it matters for your setup:
- 6x More "Memory": TurboQuant squashes the KV cache down to 3 or 4 bits with zero accuracy loss (Zandieh et al., 2025). That means I can have a conversation six times longer than before on the exact same hardware.
- Insane Speed: On professional chips like the H100, this method is up to 8x faster (Google Research, 2026). Even on our home GPUs, it means the text will start appearing on the screen much faster during long sessions.
- It’s "Data-Oblivious": This is the kicker for me. Usually, to get these savings, you have to "train" the compression on specific data. TurboQuant doesn't care what you're talking about. It works on medical data, code, or creative writing right out of the box.
The Real-World Impact: May 2026 and Beyond
We are already seeing the ripple effects. Since the announcement in late March, the industry has shifted. Tech analysts are noting that this might actually lower the cost of AI subscriptions because companies can now fit six times more users on a single server (ZDNET, 2026).
For me, it means my "old" RTX 3080 just got a new lease on life. I don't need the $2,000 upgrade anymore. I just need better math—and Google just gave it to us.
References
- Fofadiya, D. (2026). TurboQuant: The KV Cache Compression That Crashed Memory Stocks. Darshan Fofadiya Research. Link
- Google Research. (2026). TurboQuant: Redefining AI efficiency with extreme compression. Google Research Blog. Link
- o-mega.ai. (2026). Google TurboQuant: The 2026 LLM Compression Guide. Link
- Vasisht, A. (2026). KV Cache Is Eating Your VRAM. Here's How Google Fixed It. Towards Data Science. Link
- ZDNET. (2026). What Google's TurboQuant can and can't do for AI's spiraling cost. Link
More posts


